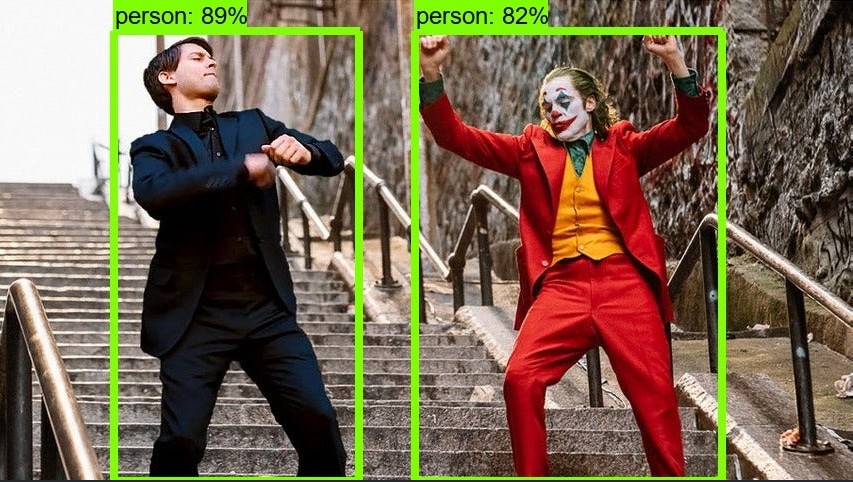
Object Detection with YOLOv3
| SW dependencies |
|---|
| NVIDIA Graphic Driver |
| CUDA-Toolkit >= 7.5 (GPGPU 연산) |
| 5.x <= cuDNN <= 7.x (DL 고성능 연산용) |
| 3.x <= OpenCV <= 3.4.0 (미디어 포맷 인식 및 결과 Grid 그리기) |
| CMake >= 3.8 (C++ 소스코드 빌드) |
| Test Environment | |
|---|---|
| CPU | Intel Xeon(R) CPU E5-2620 16core(8x2) 2.1GHz |
| RAM | 128G |
| GPU | Titan X (Pascal) (*1ea), computer capability : 6.1 |
| OS | Ubuntu 16.04 (Xenial Xerus) |
1. Container화
테스트 실행에 필요한 환경을 컨테이너로 압축하여 구성한다.
인계받은 자료에 의하면 소스 코드 빌드를 마치고
1 | ./DeepVisionXPlayer [cfg file] [Data cfg file] [weight file] [테스트 미디어 파일] |
으로 파일을 실행한다.
우선 요구환경을 아래와 같이 순서대로 컨테이너화 하여 구축한후
아래처럼 [테스트 미디어 파일]을 argument로 설정하여 실행하도록 한다.
1 | docker run yolo:v1 [테스트 미디어 파일] |
컨테이너화 단계 중 OpenCV3.4 를 활용하면 Faster RCNN이나 SSD등의 객체 인식 프레임워크 테스트 환경으로도 활용할 수 있을 것으로 예상된다.
1.1 NVIDA 드라이버 설치
Nouveau 관련 설정
Linux상에서 NVIDIA 그래픽 드라이버 설치시 nouveau라는 그래픽드라이버가 충돌을 일으키므로 해제하라는 경고 메시지를 만날 수 있다. nouveau는 Linux에 기본적으로 내장된 그래픽 드라이버로 이를 커널로 부터 해제시켜야 정상적으로 설치를 진행할 수 있다.
Centos7 상에서는 grub에 설정파일의 GRUB_CMDLINE_LINUX항목 끝에 아래 내용을 입력하여 해결할 수 있다.
1 | vi /etc/default/grub |
내용을 입력하였으면 저장wq!하고 커널의 설정을 변경하였으므로 변경된 내용을 아래 명령어로 반영시킨다.
1 | grub2-mkconfig -o /boot/grub2/grub.cfg |
드라이버 설치
Nvidia 드라이버 홈페이지로 부터 드라이버 설치를 진행한다. 설치할 서버의 GPU 장비에 맞는 버전을 찾아 설치한다.
1 | wget http://kr.download.nvidia.com/XFree86/Linux-x86_64/390.77/NVIDIA-Linux-x86_64-390.77.run |
다운로드된 설치파일은 실행권한이 없으므로 아래와 같이 권한을 부여한다.
1 | chmod a+x NVIDIA-Linux-x86_64-390.77.run |
실행권한이 부여되었으므로 설치를 진행한다.
1 | sh NVIDIA-Linux-x86_64-390.77.run |
설치가 완료되면 아래 쉘 명령어로 GPU 장비 상태를 확인한다.
1 | nvidia-smi -L |

1.2 Docker / Nvidia-docker 설치
아래 yum 명령어로 간단하게 docker 설치가 가능하다
1 | yum install docker |
docker 설치가 완료되면 아래 명령어를 통해 docker가 설치된 정보를 확인할 수 있다.
1 | docker info |
아래 명령어를 통해 docker로 생성되는 컨테이너들의 위치를 확인할 수 있다.
1 | docker info | grep 'Docker Root Dir' |
기본적으로 /var/lib/docker위치에 컨테이너를 생성하는데 컨테이너가 많거나 무거워질 경우를 대비해
충분한 공간이 있는 파티션의 디렉토리로 옮기기로 한다.
현재 /data 디렉토리에 3TB 하드 두개를 Raid 0 포맷으로 mount 시켰기 때문에 해당 마운트지점에 컨테이너를 저장할 경로를 생성한다.
1 | mkdir /data/docker-img |
그 후, docker의 root dir 변경을 위해 아래 처럼 /etc/sysconfig/docker 파일을 열어서
1 | vim /etc/sysconfig/docker |
OPTIONS 값 앞에 아래 처럼 --graph와 --storage-driver 옵션을 추가해준다.
OPTIONS=’–selinux-enabled –log-driver=journald –signature-verification=false –graph=/data/docker-img –storage-driver=overlay‘
설정이 변경되었으므로 docker 서비스를 재시작시켜준다.
1 | systemctl restart docker |
컨테이너 저장경로가 변경되었는지 확인한다.
1 | docker info | grep 'Docker Root Dir' |
테스트를 위해 간단한 컨테이너를 아래 처럼 생성해볼 수 있다.
1 | docker run hello-world |
기본 docker 만으로는 서버에 장착된 그래픽카드를 인식할 수 없다. NVIDIA에서 개발한 NVIDIA-Docker를 이용하여 컨테이너를 생성하면 그래픽카드를 container에서 인식할 수 있다.
NVIDIA-Docker
설치는 홈페이지에 나오는 instruction을 따르기로 한다. 아래 쉘 명령어 조합들을 따라서 입력해준다.
1 | distribution=$(. /etc/os-release;echo $ID$VERSION_ID) |
입력이 완료되면 아래 docker 명령어로 docker상에서 nvidia-smi명령어 실행을 확인할 수 있다.
1 | docker run --rm nvidia/cuda nvidia-smi |
1.3 CUDA (9.x) 및 cudnn7 컨테이너화
Public Registry인 Docker Hub로 부터 CUDA 및 cudnn이 설치된 컨테이너를 pull할 수 있다.
현재 테스트를 위해서 9.0-cudnn7-runtime 버전의 이미지를 생성하도록한다.
1 | docker pull nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04 |
생성된 이미지로 컨테이너를 생성하여 bash터미널로 접속한다.
1 | docker run -it nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04 /bin/bash |
컨테이너의 OS버전과 그래픽드라이버를 확인한다.
1 | cat /os-release |
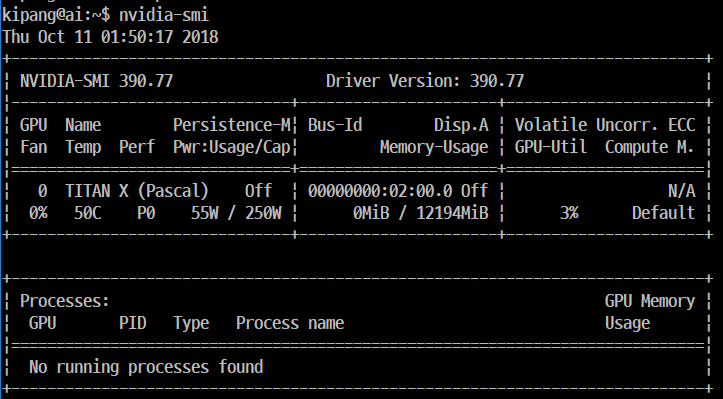
CUDA 설치를 위해선 아래 명령어를 입력한다.
1 | nvcc -V |
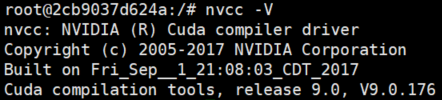
1.4 CMake 컨테이너화
컨테이너 나가기: shift+p + shift+q
YOLOv3이 CMake 3.8+ 이상의 버전을 요구하므로 공식 release 버전중 하나인 3.11.4버전을 설치해본다.
아래처럼 Dockerfile 파일을 생성한다.
1 | mkdir cmake-docker |
1 | FROM nvidia/cuda:9.0-cudnn7-devel |
docker build 명령을 통해 작성한 Dockerfile로 이미지를 생성한다.
1 | docker build [Dockerfile 경로] -t [이미지명]:[태그] |
1 | docker build cmake-docker -t cmake:3.11.4 |
생성된 이미지로 cmake 버전을 확인한다.
1 | docker run -it --rm cmake:3.11.4 cmake --version |
1.4 OpenCV 컨테이너화
디렉토리를 새로 생성하여 아래와 같이 Dockerfile을 만든다.
1 | mkdir opencv-docker |
OpenCV의 버전은 3.4.0을 설치한다.
1 | FROM cmake:3.11.4 |
1 | docker build opencv-docker -t opencv:3.4.0 |
여기까지가 컨테이너상에 CUDA + CUDNN + Cmake + Opencv 를 설치하는 과정이다.
이제 YOLOv3의 소스를 받아 실행해본다.
1.5 YOLOv3
Opencv컨테이너를 생성하여 쉘로 접속한다.
1 | docker run -it --rm opencv:3.4.0 /bin/bash |
아래 명령어를 통해 Yolov3를 깃허브로부터 받는다.
1 | git clone https://github.com/AlexeyAB/darknet.git |
다운로드가 끝나면 이제 빌드를 해야하는데 Makefile를 편집기로 열어서 (vi 없으면 설치..) 수정해준다.
맨 상단에 GPU,CUDNN, OPENCV등의 옵션이 0으로 지정되어 있는데 이들을 1로 수정해준다.
1 | GPU=1 |
darknet폴더로 이동하여 빌드를 아래 명령어로 수행한다.
1 | cd darknet |
빌드가 끝나면 weight파일을 생성해야하는데 학습된 weight 샘플을 아래처럼 받을 수 있다.
1 | wget https://pjreddie.com/media/files/yolov3.weights |
가중치에 대한 cfg는 소스에 포함되어 있으므로 아래처럼 data폴더 밑의 dog.jpg이미지에 대학 객체 인식을 수행한다.
1 | ./darknet detect cfg/yolo.cfg yolov3.weights data/dog.jpg |
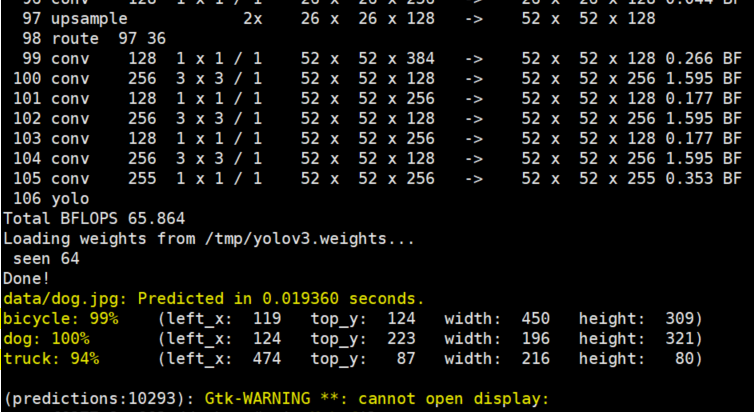
결과를 조회해보면 JPG 파일 하나에서 객체를 추측하는데 0.02초 정도로 나타난다.
또한 인식한 객체들에 대한 결과가 나타나고 Grid된 좌표에 대한 결과가 나타난다.
마지막에 GTK 경고가 나타나는데 이는 이미지를 보여줄 Window환경이나 Display가 찾을 수 없음을 의미한다.
경고 메시지가 닫히면 로컬에 predictions.png파일이 생성되고 수행결과를 확인해볼 수 있다.
1 | ls ./ |


단일 이미지파일에 대해서는 객체인식을 하는것으로 나타나므로 Video파일에 대한 객체인식을 수행한다.
테스트할 Video데이터는 carpark.mp4로 주차장 녹화 데이터이다.
1 | /darknet detector demo cfg/coco.data cfg/yolov3.cfg /tmp/yolov3.weights /tmp/carpark.mp4 |
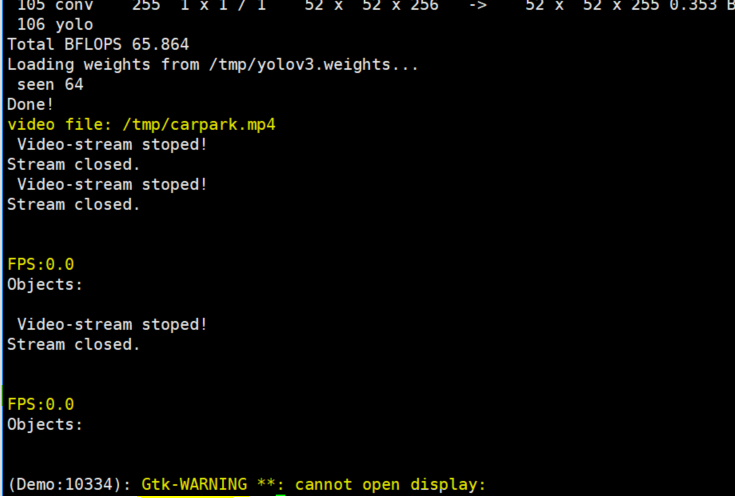
뉴럴네트워크 구성에는 성공하였으나 Video 스트림에는 실패한것으로 보인다.
로컬에서도 파일생성에 실패한것으로 나타난다.
1.6 DeepVisionX Player 테스트
DeepVisionX Player는 darknet 라이브러리를 이용하여 OpenCV 및 CUDA를 사용하여 YOLOv3으로 동영상, /assets\yolov3으로부터 실시간 객체를 탐지하는 프로그램이다.
인계받은 DeepVisionX Player의 소스코드를 container로 옮긴다.
1 | cp -r /tmp/deep-vision-x-player/ / |
빌드를 위해 build디렉토리를 생성하고 컴파일을 진행한다.
1 | mkdir build |
빌드에 성공하였다면 video 파일에 대한 객체인식을 진행하고 명령어 입력 방식은 아래와 동일하다
1 | build/bin/DeepVisionXPlayer [yolo cfg 파일] [train cfg 파일] [수행할 video 파일] |
테스트를 위해 실행한 명령어는 아래와 같다
1 | ## 소스파일 디렉토리로 이동한다. |
수행결과:

마찬가지로 뉴럴 네트워크 구성에는 성공하였으나 video 파일 인식에는 실패하였다.
2. Ubuntu 16.04 Desktop
GPU서버의 Host OS를 Ubuntu 16.04로 재설치하여 진행한다.
OpenCV, Nvidia 그래픽 드라이버를 잡는 방법은 컨테이너화 작업때의 스크립트를 재사용하고
CUDA-Toolkit, cuDNN 설치는 추가적인 작업을 진행하도록 한다.
2.1 CUDA-ToolKit 9.0, cuDNN 7 설치
우선 CUDA-Toolkit을 설치하는데 최신 버전인 9.2버전을 설치하지 않고 9.0 버전을 설치한다.
아래 그림과 같이 Ubuntu 16.04 버전에 해당하는 설치파일을 다운로드 받는다.
다운로드한 CUDA 설치 파일 경로로 이동하여 실행시킵니다.
1 | cd ~/Downloads |
설명문이 나오면 Enter 혹은 space 를 입력하여 끝까지 읽고 (Ctrl + c 로 스킵 가능) 다음처럼 진행
1 | ""Do you accept the previously read EULA? accept/decline/quit: accept |
다음으로 cuDNN 설치로 진행한다.
cuDNN은 Cuda Deep Neural Network 의 약자로 CUDA에서 인공신경망 구조를 생성할 수 있도록 지원하는 NVIDIA에서 제공하는 라이브러리입니다.
NVIDIA의 cuDNN 다운로드 링크를 접속하여 간단한 멤버십 가입을 통해 다운로드를 진행합니다.
다운로드 URL : https://developer.nvidia.com/rdp/cudnn-download
CUDA 9.0 버전의 제일 상단의 cuDNN v7.1.4 Library for Linux 을 선택하여 다운로드합니다. (tgz 파일)
다운로드 받은 파일 경로로 이동하여 압축을 해제합니다.
1 | cd Downloads |
압축을 해제하면 cuda 폴더가 생성되는데, 내부 파일들을 다음과 같이 복사합니다.
1 | sudo cp cuda/include/cudnn.h /usr/local/cuda/include |
모든 과정이 끝나면 홈디렉토리로 이동하여 .bashrc 파일에 CUDA의 PATH를 등록합니다.
1 | sudo vi ~/.bashrc |
내용을 저장하고 닫습니다.
bashrc의 변경사항을 바로 반영하도록 다음 명령을 실행합니다.
1 | source ~/.bashrc |
설치가 잘 완료되었는지 확인하기 위해 nvcc -V를 통해 CUDA 버전을 확인할 수 있습니다.
1 | nvcc -V |
2.2 YOLO_mark를 이용한 데이터 labeling
souce : /home/kipang/workspace/Yolo_mark
기존의 coco dataset, 80개의 클래스의 객체인식외에 Custom으로 클래스 데이터셋을 생성하는 작업을 진행합니다.
Yolo_mark는 custom 데이터를 생성하기 위한 marking 툴을 제공합니다.git명령을 통해 다음과 같이 github의 yolo-mark오픈소스를 git clone하여 빌드합니다.
1 | git clone https://github.com/AlexeyAB/Yolo_mark.git |
빌드가 끝나면 yolo_mark 바이너리 실행파일이 생성된 것을 확인한다.
x64/Release/data/obj.data파일을 편집기로 열어서 학습될 객체의 갯수를 지정해준다.
1 | vi x64/Release/data/obj.data |
1 | classes=2 ## 클래스 갯수 |
train, valid는 각각 학습,검증에 사용될 이미지파일의 경로를 가지고 있어야한다.
1 | 예시) |
obj.names 파일에는 객체명을 저장한다.
1 | 예시) |
위와 같이 .jpg 학습파일, train.txt 이미지경로, obj.names의 작업이 끝나면
아래와 같이 argument를 주어 yolo-mark를 실행한다.
1 | yolo_mark <JPG파일 경로> <train.txt 경로> <obj.names 경로> |
실행하게 되면 아래 그림처럼 labeling 작업 툴 화면이 나타나게 된다.
실행화면:
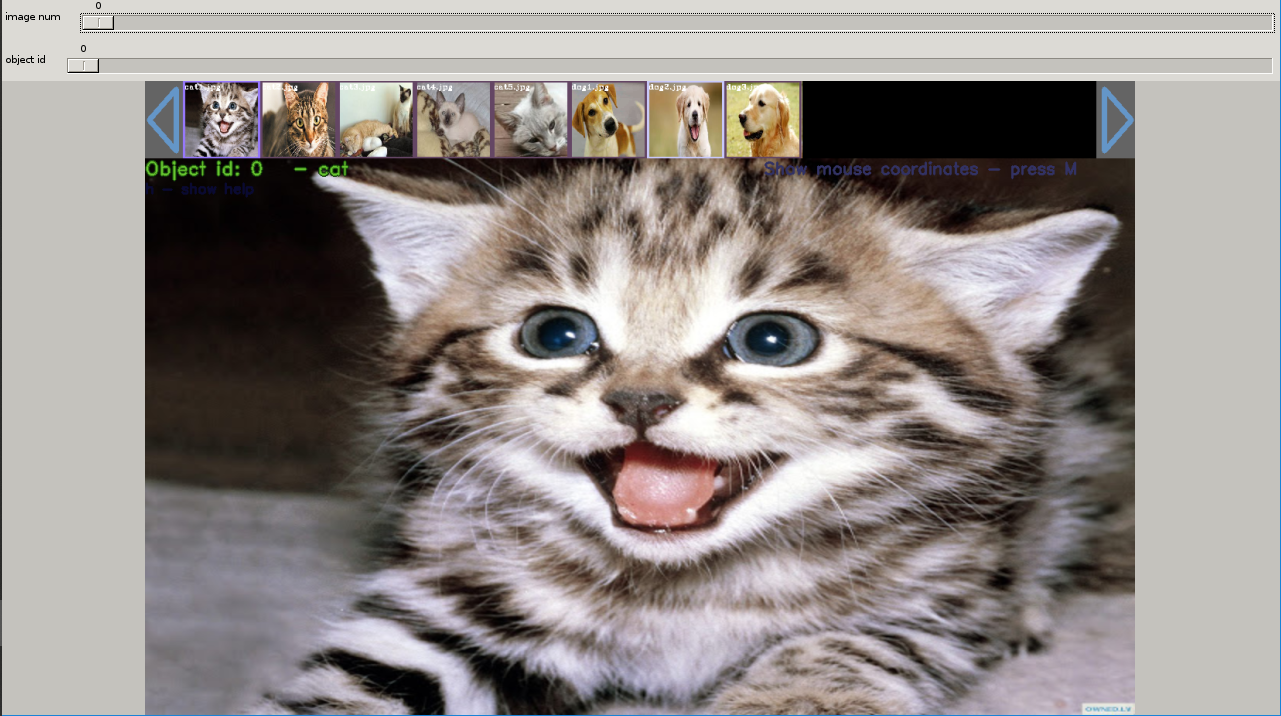
Keymap:
| Key | 동작 |
|---|---|
| 마우스 드래그 & 드롭 | box 그리기 |
| 숫자키 0~9, ←,→ | 객체 id 지정 |
| space | 다음 /assets\yolov3 |
| c | 모든 box 지우기 |
| z | 취소,undo |
| ESC | 종료 |
여러 객체가 있을때 숫자키, 좌우키로 객체 id를 변환하면서 지정할 수도 있다.
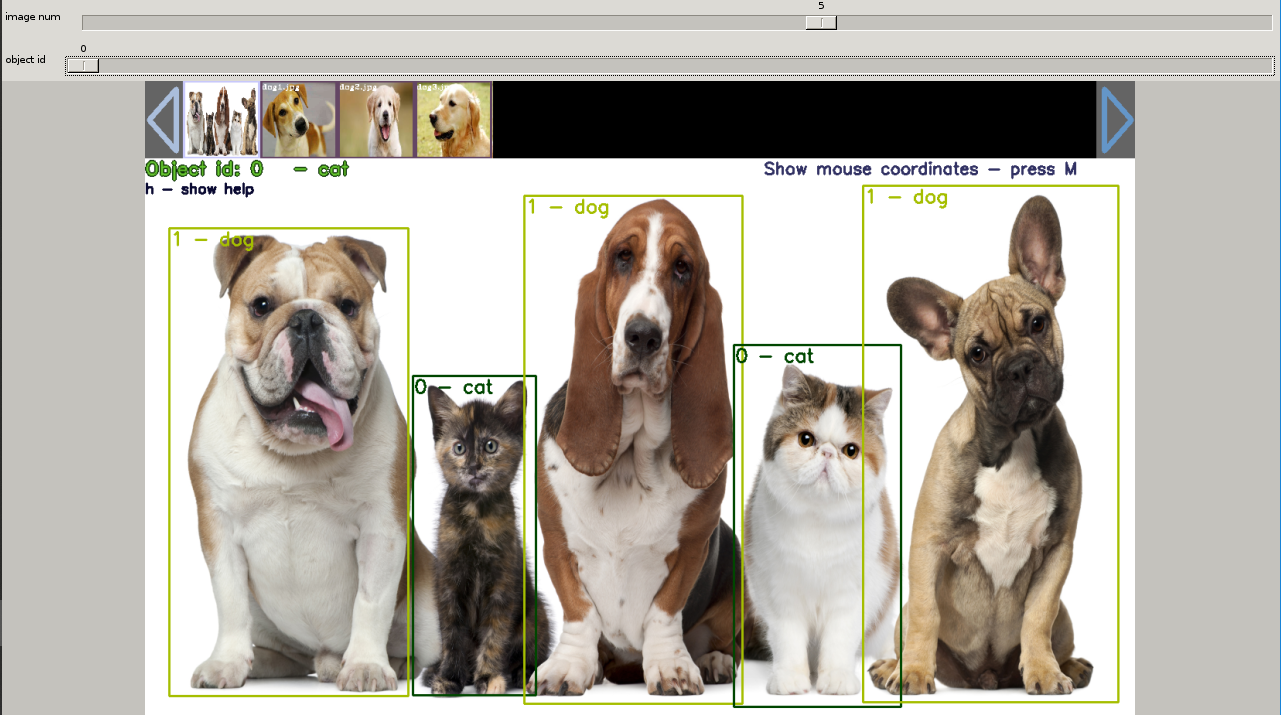
Box를 지정할때 마다 jpg 폴더에 해당파일의 .txt가 생성되며 내용에는
1 | 객체id <x> <y> <width> <height> |
처럼 box 작업을 한 내역이 저장되어 있다.
Custom 데이터생성은 Yolo_mark를 사용하거나 LabelImg : https://github.com/tzutalin/labelImg 으로도 작업할 수 있다.
2.2.1 Video frame 저장
yolo_mark에서는 Video 파일의 특정 N frame마다 JPG Image로 저장하는 기능을 제공한다.
1 | ./yolo_mark <프레임 저장경로> cap_video <Video파일> <N> |
N을 10으로 지정하면 10번째 프레임마다 지정한 경로에 JPG로 저장된다.
저장된 프레임 데이터에 labeling 작업을 진행하여 학습데이터로 활용할 수 있다.
2.3 Custom 데이터셋 학습
2.3.1 Preparation
custom 데이터셋으로 학습을 진행하기 위해 앞서 진행하던 Yolo-mark의 x64/Release/yolo-obj.cfg파일을 수정한다.
1 | vi x64/Release/yolo-obj.cfg |
내용 하단의 244줄, 230줄 두 부분을 수정해야 한다.
1 | [convolutional] |
filters에 convolutional레이어의 필터값을 넣는데 다음과 같은 식에 따라 입력해준다.
1 | Yolov2 : (클래스수 + 5) x 5 ex) 클래스: 2, filter : 35 |
classes에는 클래스 갯수를 입력해준다.
다음으로 darknet을 실행할 수 있는 경로로 이동하여 아래와 같이 학습을 진행한다.
2.3.2 Training
convolutional layer를 구성하기 위해 사전에 학습된 가중치 데이터를 다운로드 받는다. (76MB)
1 | wget http://pjreddie.com/media/files/darknet19_448.conv.23 |
다운로드가 끝나면 custom dataset 레이블링 작업에 사용된 obj.data,obj.names,train.txt, darknet19_448.conv.23 파일을 darknet 실행경로로 옮겨준다.
아래와 같이 darknet detector train명령을 통해 학습을 실행시킨다.
1 | darknet detector train data/obj.data cfg/yolo-obj.cfg darknet19_448.conv.23 -dont_show |
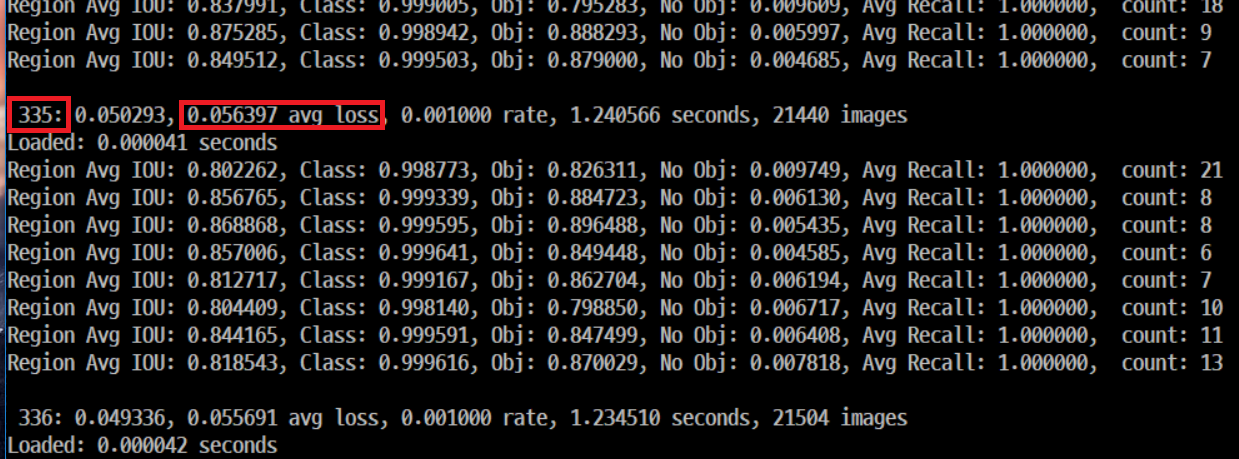
학습을 진행하면 위 그림과 같이 학습단계가 log형식으로 터미널상에 뿌려지는데
왼쪽부터가 학습 iteration 횟수, avg loss 가 error rate 이다.
Yolo document 에 따르면 클래스당 적어도 2000 번의 iteration을 수행해야한다고 나타나있다.
즉, 클래스가 3종류이면 적어도 3 x 2000=6000번 정도의 iteration을 진행해야 한다.
또한 avg loss는 0.xxxxx 이하로 나타날때 Overfitting이 발생할 수 있으므로 해당 수치정도까지 학습을 진행하도록 권장되어있다.
학습은 100번의 iteration 마다 obj.data에 명시해둔 backup 경로에 checkpoint 형식으로 저장된다.

학습도중 예기치 못하게 종료되었을때 backup 된 weight로 중단된 지점부터 다시 학습을 진행할 수 있다.
1 | darknet detector train data/obj.data cfg/yolo-obj.cfg <weight파일> -dont_show |
학습을 마쳤다면 테스트를 아래와 같이 명령어로 수행해 볼 수 있다.
1 | darknet detector test data/obj.data cfg/yolo-obj.cfg <weight파일> <Image 파일> |
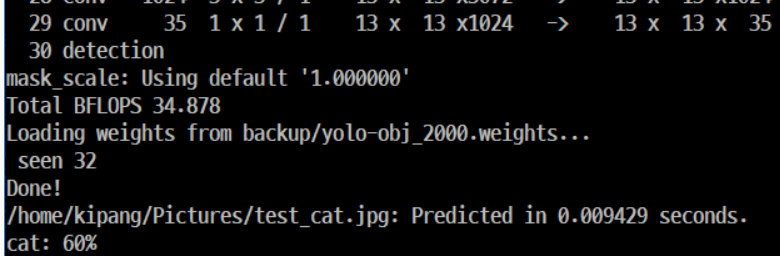

2.4 번호판 인식 테스트
2013장의 레이블링된 번호판 데이터를 45000번 학습된 Custom weight 데이터를 이용하여 블랙박스 영상에서 번호판 객체만을 인식시켜보는 테스트를 진행한다.
학습에 사용된 데이터는 1675장의 정지된 차량이미지 + 338장의 동영상 프레임 이미지이다.
다음으로는 각 Neural Network 프레임워크 별로 영상/이미지 객체 인식을 수행해본다.
weight 위치 :/data/plate/yolo-cits_final.weights
2.4.1 pjreddie/darknet
source : /home/kipang/workspace/pjreddie-darknet
.data, .cfg 위치 : /data/plate/cits.data, /data/plate/yolo-cits.cfg
darknet은 Yolo구현에 필요한 Neural Network 프레임워크이다. C++, CUDA로 작성되었으며 Github에 오픈소스로 공개되어 있다.
darknet 소스를 내려받으면 Makefile을 수정하여 GPU 호환을 활성화시킨다.
1 | git clone https://github.com/pjreddie/darknet |
빌드가 끝나면 darknet 실행 바이너리 파일이 생성된다.
Custom weight 데이터로 객체인식을 수행하기 위해선 아래와 같이 실행해준다.
1 | darknet detector demo <.data파일> <.cfg파일> <weight파일> <media파일> -thresh <임계값> |
-thresh <임계값>은 프레임에 클래스가 인식되었을때 해당 임계값을 초과할때만 객체로 인식하기위한 옵션이다. (default = 0.25, 25%)
따라서, 임계값을 조절하여 객체인식률을 조절할 수 있다.
1 | ## For Image |
실행 시 Video Player가 동작하여 결과를 Display 해준다.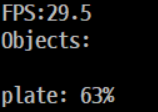
2.4.2 alexyAB/darknet
source : /home/kipang/workspace/alexyAB-darknet
2.4.1 pjreddie/darknet 프로젝트를 fork하여 개발된 프레임워크로 몇가지 추가기능과 성능개선이 포함되어있다. Github 링크 상에 오픈소스로 공개되어있다.
빌드 순서
1 | cd darknet |
추가기능은 -thresh 처럼 flag를 실행문 끝에 추가하여 아래 동작들을 수행할 수 있다.
1 | ## Player 화면 숨기기 |
명령어를 실행하게 되면 Frame per Second로
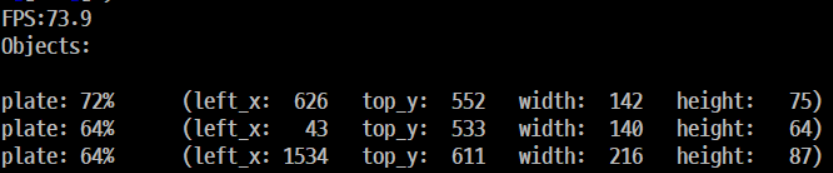
와 같이 나타난다.
2.4.3 DeepVisionX Player
source : /home/kipang/workspace/deep-vision-x-player
기존 darknet 기반의 프레임워크로 stream 객체 인식시 동작하는 Video Player가 변경되었으며 실행시 cfg와 data파일의 flag 입력 순서가 다르다.
빌드순서
1 | cd deep-vision-x-player |
1 | build/bin/DeepVisionXPlayer <.cfg파일> <.data파일> <weight파일> <Media파일> |
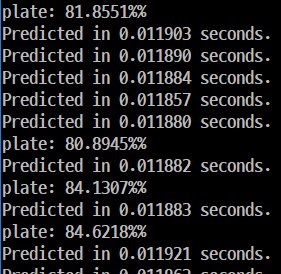
동영상의 프레임별 객체를 스캔/탐지하는데 걸린 시간, 인식된 객체에 대한 confidence 수치를 나타나게 된다.