
람다 아키텍쳐
Lambda Architecture, 람다 아키텍쳐
데이터 처리 방법은 다양하고 넓게 분류해보면 배치, 실시간 으로 나뉜다. 원하는 방식을 사용하여 원하는 결과를 얻을 수 있지만 어떤 상황에서는 두 처리 방법의 데이터가 모두 필요한 경우가 있다. 이때 데이터 병합 문제가 발생할 수 있는데 Lambda Architecture, 람다 아키텍쳐 를 적용하면 문제를 해결할 수 있다.
람다 아키텍쳐는 높은 확장성과 분산 컴퓨팅 성능을 제공하며, 배치와 실시간 처리를 통해 결과적으로 일관성 있는 데이터를 제공한다.
데이터 흡수 계층, Data Ingestion Layer
- 전달되는 데이터의 속도를 제어할 수 있어야한다.
- 변화하는 작업 부하에 따라 확장이 가능한 유연성
- Fault-tolerant 및 fail-over 지원
- 멀티 스레드 및 멀티 이벤트 처리 가능
- 데이터를 요청하는 계층에 맞게 빠르게 변환가능
- 데이터는 purest form (순수한) 형태를 유지해야한다.
데이터 흡수 계층은 메시지 전달 계층의 메시지를 소비하고 람다 계층으로 흡수하는데 필요한 변환을 수행해 다음 계층의 저장 및 처릴르 쉽게 만들어 준다.
이 계층은 일관된 방식으로 메시지를 소비하는 것을 보장해야 하며, 이를 통해 모든 메시지가 유실되지 않고 최소 한 번은 처리되게 해야 한다.
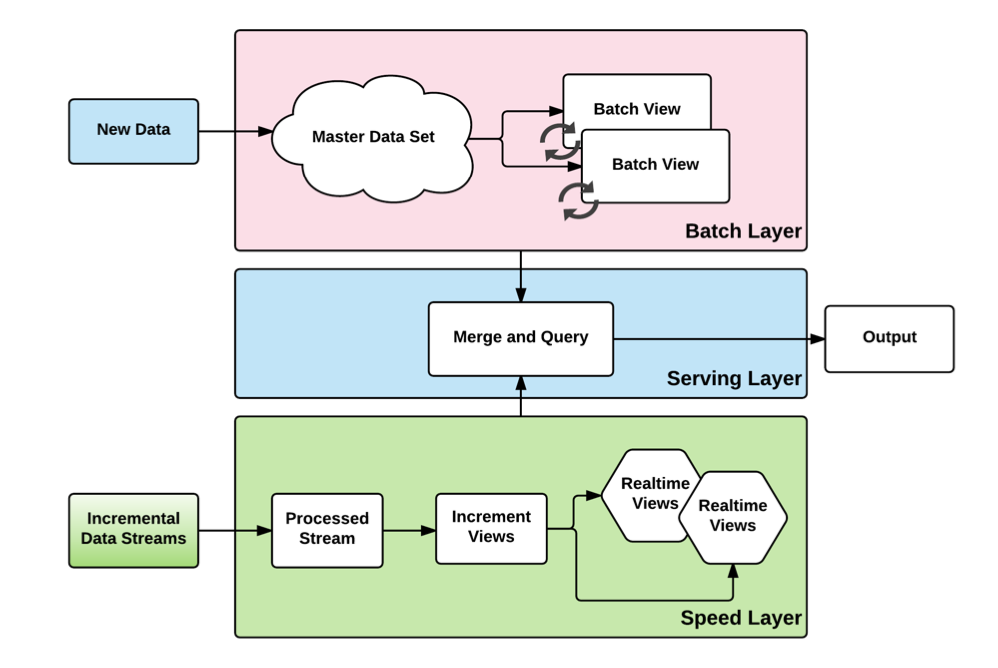
람다 계층
일반적으로 배치 계층과 속도 계층으로도 알려진 실시간 계층을 포함한 두개의 계층으로 구성된다.
배치 계층, Batch Layer
흡수된 데이터의 처리
대규모 데이터를 처리하는 가장 전통적인 방법이며, 대게 오랜 시간에 걸쳐 수행된다.
- 원본 데이터를 모델링된 데이터로 변환하는 것이 주 목적
- 시스템 자원을 최대한 활용해 흡수된 데이터를 처리함
- 장시간 연산이 요구되는 데이터에 대해 높은 품질의 데이터를 제공
- Falut-tolerant 지원
- 흡수된 원본 데이터에 대한 모델링 데이터를 생성을 하기위해 머신 러닝과 데이터 분석 처리를 지원
- de-duplication, 중복 제거등을 통해 데이터 전체적으로 품질 향상을 제공
Hadoop은 전통적인 배치 처리 방식보다 더 효율적이고 확장성있는 배치 처리가 가능한 프레임워크와 기술을 모두 제공한다. 하둡 기반의 배치 처리는 데이터와 처리의 분산을 하부에 있는 하둡 프레임워크가 담당하게 함으로써 map/reduce 작어비 특정 데이터 처리에만 집중할 수 있게 하므로 전통적인 방식으로 구현된 배치 처리에 비해 엄청난 성능 향상을 제공한다.
Map/Reduce 패러다임은 메인프레임의 등장 이후 많은 어플리케이션에서 활용해 왔기 때문에 새로운 개념이 아니다. 배치를 여러 과정으로 나눈 후 단일 출력을 생성하기 위해서 모든 출력물을 하나로 모으는 것이다.
속도 계층, Speed Layer
근실시간 데이터 칠
람다 아키텍처의 실시간 처리 계층이다. 데이터는 흡수되는 즉시 처리되며, 처리된 데이터는 저장 계층에 저장된다.
- 흡수된 데이터에 대한 실시간으로 처리하는 작업을 수행
- 높은 동시성을 지원 및 데이터 처리 기능, 신속하고 효율적으로 수행되야함
- 실시간 데이터 모델을 생성할 수 있어야 한다.
- 처리 대상이 쌓이지 않도록 저장 계층에 빠르게 접근할 수 있어야 한다.
- 흡수 계층으로 부터 분리 되어야 한다.
- 요건에 맞는 데이터를 제공하기 위해 배치 처리도니 데이터 세트와 병합할 수 있는 모델을 생성할 수 있어야 한다.
초기에는 스트리밍 기술로 Flume과 HDFS를 사용했으며, 실시간 처리에 하둡 배치 처리에 의존하는 것이 적합하지 않다는 것은 빠르게 증명되어, 이에 특화된 개별 프레임워크가 만들어졌다.(Spark)
초기에는 개별 프레임워크들은 Hadoop 에코들과 잘 연동되지 않았지만 기술의 발전하면서 운영과 관리의 단순화를 위해 하둡과 통합되었다.
데이터 저장 계층, Data Storage Layer
모든 데이터 저장
람다 아키텍쳐에서 흡수된 데이터에 대한 처리는 두가지(배치, 속도)가 있고, 각 처리에마다 요구되는 데이터는 매우 다르다.
예를 들어 배치 처리의 경우 HDFS 저장계층에 적합한 순차적 읽기와 쓰기 연산이 일어난다. 하지만 실시간 처리의 경우 빠른 조회와 빠른 쓰기가 필요하므로 HDFS는 적합하지 않다. 실시간 처리를 위해선 indexed data(색인) 유형의 데이터 계층이 필요하다.
- 순차(serial) 연산과 임의(random) 연산을 모두 지원해야 한다.
- 데이터 솔루션에 적합한 활용 패턴에 따라 계층화되야 한다.
- 배치뿐만 아니라 실시간 처리를 위한 대용량 데이터를 제어할 수 있어야 한다.
- 다양한 구조를 갖는 데이터 저장소를 지원하기 위해 유연성과 확장성을 제공해야 한다.
제공 계층, Serving Layer
데이터 제공 및 export
데이터를 소비하는 application으로 최종 형태의 데이터를 delivery한다. 서비스를 통해 데이터를 제공하는 것이 일반적. 이런 서비스를 데이터 서비스라고 함.
데이터 전송을 위해 다양한 프로토콜을 지원할 수 있다. 데이터가 외부로 나가는 방법은 요청에 의한 응답과 규약에 따른 일반적 전송으로 나뉠수 있다.
- 데이터를 소비하는 application으로 제공할 수 있는 다양한 메커니즘을 제공
- 데이터를 소비하는 application과 맺은 규약을 준수해야한다.
- 배치, 실시간으로 처리된 데이터에 대한 view를 지원
- 확장성이 있어야 하며, 소비 대상 application에 빠르게 대응해야 한다.
데이터 획득 계층, Data acquisition Layer
데이터 원천에서 데이터 획득
관계형 데이터베이스 XML/JSON 데이터, 시스템간에 오가는 메시지등이 정형 데이터,
이메일, 채팅, 문서 등의 반정형 데이터를 다룬다.
획득 계층의 핵심은 데이터 레이크에서 처리할 수 있는 형태의 메시지로 데이터를 변환하는 것이다. 따라서 다양하게 정의된 스키마 정의를 수용할 수 있는 유연성을 가져야 하고, 동시에 전체 메시지를 끊임없이 데이터 레이크로 밀어 넣을 수 있는 빠른 접속 메커니즘을 갖고 있어야 한다.
- Falut-tolerant
- 메시지 저장용 로컬 버퍼를 지원해야함
메시지 전달 계층
데이터 전송 보장
데이터 레이크 아키텍처에서 메시지 지향 미들웨어를 형성해 메시지의 전달을 보장하면서 여러 계층을 분리하는 핵심 계층이다.
메시지 전달을 보장하려면 메시지가 저장되어야 한다. 메시지 저장은 일반적으로 내부디스크에서 이루어진다.
일반적으로 HDD로도 충분하지만, 초당 수백만 메시지를 처리해야하면 SSD를 사용하는 것이 I/O에서 유리하다.
또 다른 기능으로는 Queue 적제, Queue 인출 능력이다. 대부분의 메시징 프레임워크는 메시지의 발행과 소비를 관리하기 위한 적재 및 인출 메커니즘을 제공한다. 모든 메시징 프레임워크는 내부 자원에 접속할 수 있는 자체 라이브러리를 제공한다.
모든 메시지 지향 미들웨어는 일반적으로 Queue와 Topic 이라는 메시징 구조를 이용해 두가지 유형의 통신을 지원한다.
- Queue는 하나의 Consumer가 모든 메시지를 단 한번만 소비하게 하는 point-to-point 통신에 사용된다.
- Topic은 메시지가 한 번 발행된 후 consumer에 의해 여러번 소비 가능한 발행/구독 메커니즘을 제공하는데 사용된다. 따라서 메시지는 컨슈머마다 한 번씩 여러번 소비될 수 있다.
Lambda Architecture 원칙
Fault-tolerance, 내고장성
하드웨어, 소프트웨어, 인간의 실수에 대한 내고장성은 람다 패턴의 일부가 되야 한다.
빅데이터를 다루기 때문에 어떤 유형의 장애이던 복구가 가능해야한다.
Immutable Data, 데이터 불변
다양한 데이터 원천으로 수집된 데이터들은 원본 형태를 유지해야 한다. 더 중요한 것은 이 데이터가 근본적으로 불변형으로 저장되야 한다는 점이다.
데이터 불변을 유지하기 위해 일정 수준의 인적 실수에 유의해야 하며, 데이터 유실과 변경과 관련된 오류 발생을 제거해야한다.
Re-computation principle, 재연산의 원칙
원본 데이터를 데이터 레이크에서 항상 사용할 수 있기 때문에 원본 데이터에 새로운 연산을 수행해 신규 요구 사항을 만족하게 할 수 있다.
이를 위해 재연산을 수행할 때 문제가 발생할 수 있는 Schema 적용 방식보다는 Schema가 없는 Schema-less 구조로 데이터를 저장한다.
람다 장/단점
장점
데이터는 원본 형태로 저장되므로, 언제든지 새로운 알고리즘이나 분석 기법 또는 신규 비즈니스 사용 사례를 적용할 수 있다. 이는 스키마를 적용해 저장하는 기존의 RDBMS 형태의 데이터 웨어하우스가 갖지 못하는 장점이다.
Namely recomputation, 재연산이라 불리는 하나의 핵심 원칙을 통해 큰 문제 없이 fault-tolerance를 얻을 수 있다.
서로 다른 역할을 하는 계층으로 서로 다른 기술을 가질 수 있으며, 확장성을 가진다.
Pluggable 가능한 아키텍처를 제공하므로, 신규 혹은 기존에 사용하는 유형의 원천 데이터를 추가하는 경우 큰 문제없이 시스템에 적용할 수 있다.
단점
복잡성, 배치와 속도계층을 계속해서 동기화하기 위한 비용과 노력이 필요하며, 지속적으로 관찰하고 제어해야한다.
유지보수 어려움
많은 기술에 대한 전문성
이 패턴은 꽤 오래 사용됐지만 관련 도구들이 미성숙한 상태이므로 아직 진화중이다.
CI/CD는 필수적이며 많은 부분을 자동화하는 것은 힘들다.
많은 고사양의 하드웨어 요구사항
같은 작업을 두 번씩 한다, 때문에 일부에서는 비난을 받기도 한다.
람다 아키텍처 응용
- 엔터프라이즈급 로그 분석
로그데이터는 큰 용량을 가지며 아주 빠르게 생성된다. 람다 패턴을 통해 실시간 로그들을 검증할 수 있으며, 지나간 로그들을 총분히 이해하고 실시간 통찰력을 얻을 수 있다.
- 센서 데이터 수집 및 분석
IoT환경에서는 많은 수의 센서 데이터를 확보하게 되면서 확장성을 지닌 솔루션인 람다 아키텍쳐를 활용하여 센서 데이터에 대한 실시간 분석이 가능하다
- 실시간 메일 플랫폼 통계
비즈니스 애플리케이션과 소셜 플랫폼에서 발생하는 대규모 데이터와 함께 이메일 마케팅 플랫폼의 역할은 매우 중요하다. 다수의 이메일 플랫폼은 전송된 이메일과 관련된 꽤 많은 양의 추적 상태별 데이터를 제공한다.
- 실시간 운동 경기 분석
경기에 대한 다양한 통계와 분석을 보여 주기 위해 이력 배치 뷰와 현재 경기의 실시간 데이터를 이용해 정보를 생성할 수 있다.
추천 엔진
보안 위협 분석
보안 위협 분석에 필요한 로그는 다양한 하드웨어와 비즈니스 애플리케이션을 포함한 여러 소프트웨어 컴포넌트에서 얻을 수 있으며, 보안 위협을 분석하기 위해 과거 데이터와 비교를 수행할 수 있다.
Kappa Architecture, 카파 아키텍처
카파 아키텍처는 람다의 간소화 버전으로 유사하지만, 배치 계층을 제거하고 속도 계층만 유지한다.
항상 처음부터 연산을 수행하는 배치 계층을 두지 않고 실시간이나 속도 계층에서 모든 작업을 수행한다.
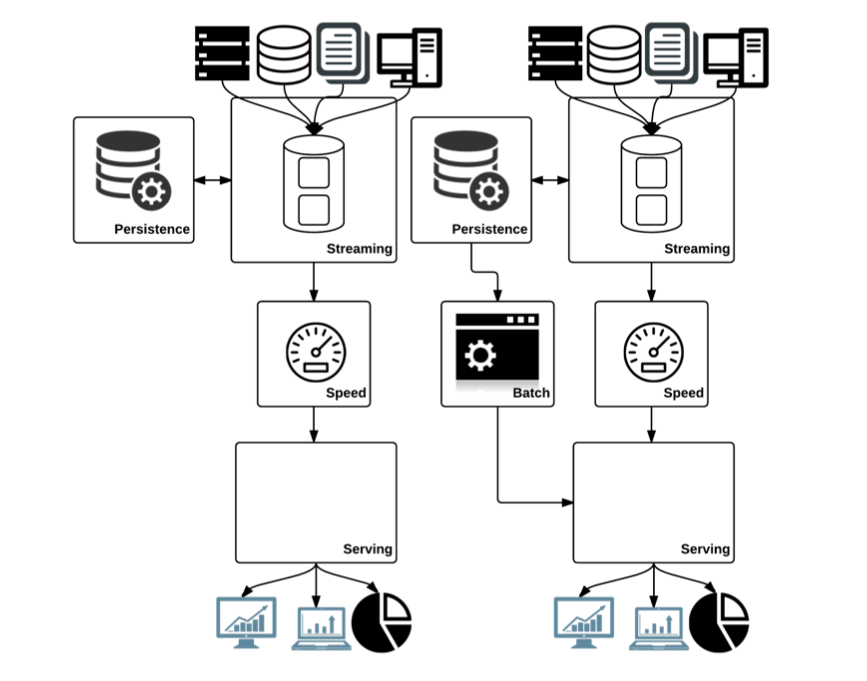
Photo by Samuel Sianipar on Unsplash